1.Group By Grouping Sets
Group by分组函数的自定义,与group by配合使用可更加灵活的对结果集进行分组,Grouping sets会对各个层级进行汇总,然后将各个层级的汇总值union all在一起,但却比单纯的group by + union all 效率要高
** 1 创建数据**
1 | CREATE TABLE employee |
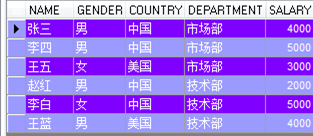
2 实例
1 | SELECT country, null department, round(avg(salary), 2) FROM employee GROUP BY country |
2.WITH ROLLUP
在group分组字段的基础上再进行统计数据。
例子:首先在name字段上进行分组,然后在分组的基础上进行某些字段统计,表结构如下:
1 | CREATE TABLE `test` ( |
存几条数据看看:
1 | INSERT INTO `test`.`test` (`Id`, `title`, `uid`, `money`, `name`) VALUES ('2', '国庆节', '2', '12', '周伯通'); |
分组统计:
1 | SELECT name, SUM(money) as money FROM test GROUP BY name WITH ROLLUP; |
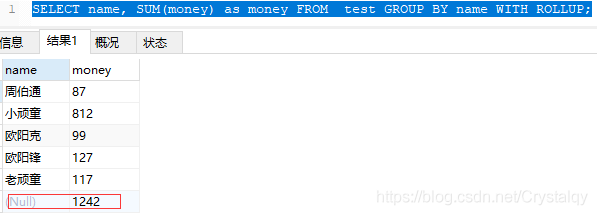
可以看到按照name分组后对money求和统计了。上面看到 null 1242, 如何搞个别名字段比如 总金额:1242呢?也可以滴,咱们继续:
1 | coalesce(a,b,c); |