创建工程
一
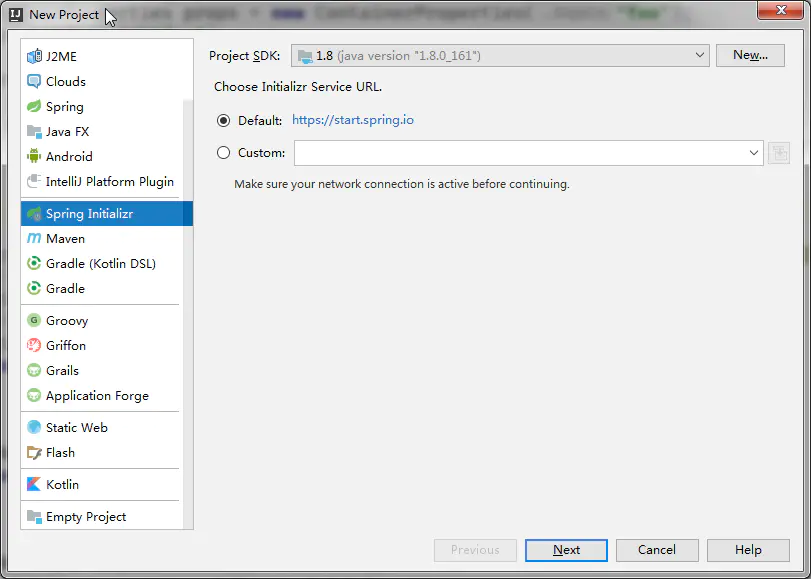
二

三
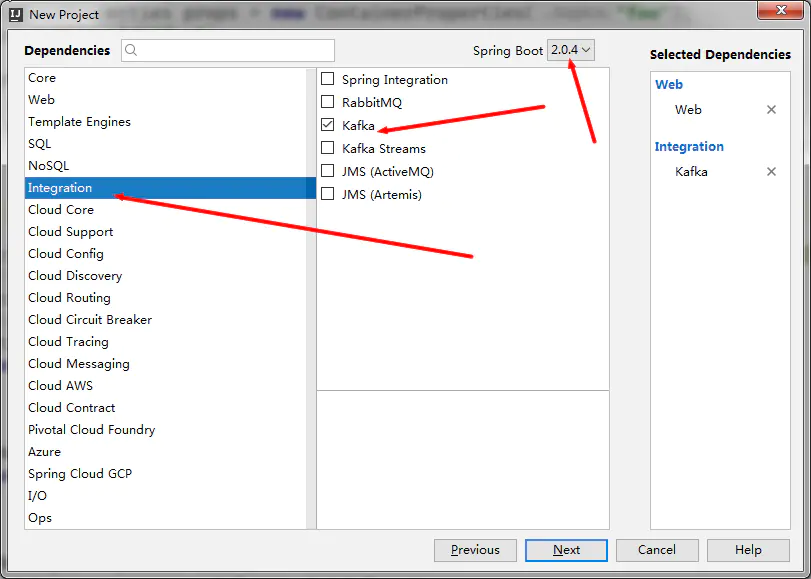
这里需要注意一下,我们导入的Spring-Kafka为2.1.8版本,SpringBoot为2.0.4的正式版,请保持版本一致、
好了,已经三秒了,真男人,你可以关闭屏幕冷静一下了,停止你那颤抖的身体。
编写第一个Demo
实现顺序
- 创建消费者和生产者的Map配置
- 根据Map配置创建对应的消费者工厂(consumerFactory)和生产者工厂(producerFactory)
- 根据consumerFactory创建监听器的监听器工厂
- 根据producerFactory创建KafkaTemplate(Kafka操作类)
- 创建监听容器
先给你们瞄一眼项目结构,记得把Kafka 启动…
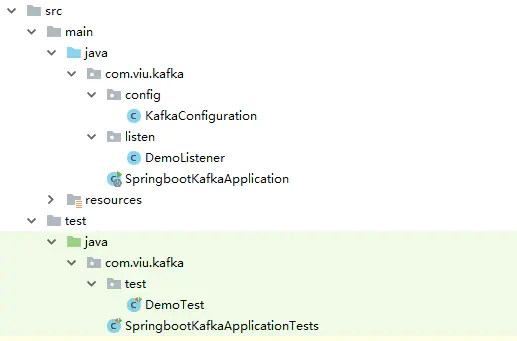
项目结构
创建KafkaConfiguration配置类
都是一些配置参数,具体的作用也在代码中写明了,值得注意的是,KafkaTemplate的类型为<Integer,String>,我们可以找kafkaTemplate的send方法,有多个重载方法,其中有个方法如下,key和data参数都为泛型,这其实就是对应着KafkaTemplate<Integer,String>。那具体有什么用呢,还记得我们的Topic中可以包含多个Partition(分区)吗,那我们如果不想手动指定发送到哪个分区,我们则可以利用key去实现。这里我们的key是Integer类型,template会根据 key 路由到对应的partition中,如果key存在对应的partitionID则发送到该partition中,否则由算法选择发送到哪个partition。
1 | public ListenableFuture<SendResult<K, V>> send(String topic, K key, V data) { |
1 |
|
创建DemoListener消费者
这里的消费者其实就是一个监听类,指定监听名为topic.quick.demo的Topic,consumerID为demo。
1 |
|
创建测试类
这里的send方法第一参数为TopicName,第二个参数则是发送的数据
1 |
|
接下来直接运行这个测试方法,我们可以看到日志中输出了我们发送的消息,这就代表我们成功的消费了测试方法中发送的消息。
1 | 2018-09-06 17:26:20.850 INFO 6232 --- [ demo-0-C-1] com.viu.kafka.listen.DemoListener : demo receive : this is my first demo |
启动项目
看清楚了是启动项目,不是测试类,我们来观察一下控制台的输出日志
首先这个是KafkaConsumer的配置信息,每个消费者都会输出该配置信息,配置太多就不做讲解了
1 | 2018-09-06 17:40:15.258 INFO 9944 --- [ main] o.a.k.clients.consumer.ConsumerConfig : ConsumerConfig values: |
这些日志就代表我们成功的创建了Consumer,由于没有做并发配置,所以现在为单个消费者模式,系统会做一个分配Partition的操作,也就是将某个Partition指定给某个消费者消费。 这里有个地方需要注意一下, 看到日志中有输出[Consumer clientId=consumer-1, groupId=demo],我们之前在监听中@KafkaListener注解中配置的id=demo,怎么就变成了groupId=demo,这是因为@KafkaListener注解如果没有指定groupId这个属性的值,则会默认把id作为groupId。
1 | 2018-09-06 17:40:15.287 INFO 9944 --- [ demo-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-1, groupId=demo] Discovered group coordinator admin-PC:9092 (id: 2147483647 rack: null) |
结束
SpringBoot2.0已经提供了Kafka的自动配置,可以在application.properties文件中配置,别问我为什么要写一堆代码来创建这些工厂,相对于properties方式我更喜欢java Config方法创建这些配置,因为很直观,虽然是有点麻烦。