昨天在写一个java消费kafka数据的实例,明明设置auto.offset.reset为earliest,但还是不从头开始消费,官网给出的含义太抽象了。** **earliest: automatically reset the offset to the earliest offset,自动将偏移量置为最早的。难道不是topic中各分区的开始?结果还真不是,具体含义如下:
auto.offset.reset 值含义解释
earliest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 latest 当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据 none topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
以下为测试详细:
通过如下命令可以查某个消费组中消费者目前的偏移量
./kafka-consumer-groups.sh --describe --bootstrap-server 192.168.235.132:9092 --group consumer.demo
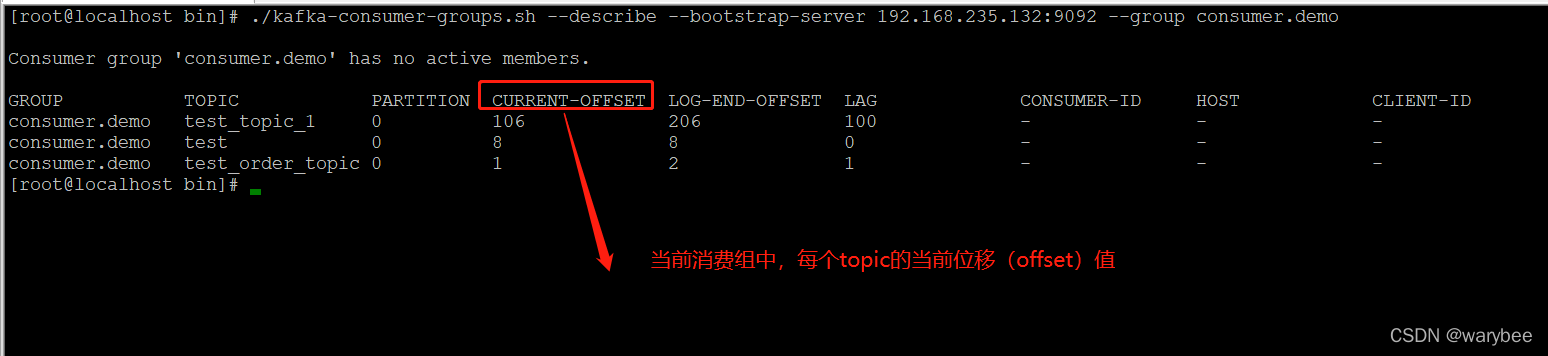
参数介绍:
CURRENT-OFFSET:当前Consumer 的当前的位移值
LOG-END-OFFSET:消息最大偏移量
LAG:消息堆积的条数
位移(offset)的作用
如果消费者一直运行,位移量的提交并不会产生任何影响。但是如果有消费者发生崩溃,或者有新的消费者加入消费者群组的时候,会触发 Kafka 的再均衡。这使得 Kafka 完成再均衡之后,每个消费者可能被会分到新分区中。为了能够继续之前的工作,消费者就需要读取每一个分区的最后一次提交的位移量,然后从位移量指定的地方继续处理。就好像书签一样,需要书签你才可以快速找到你上次读书的位置。
位移(offset)提交导致的问题
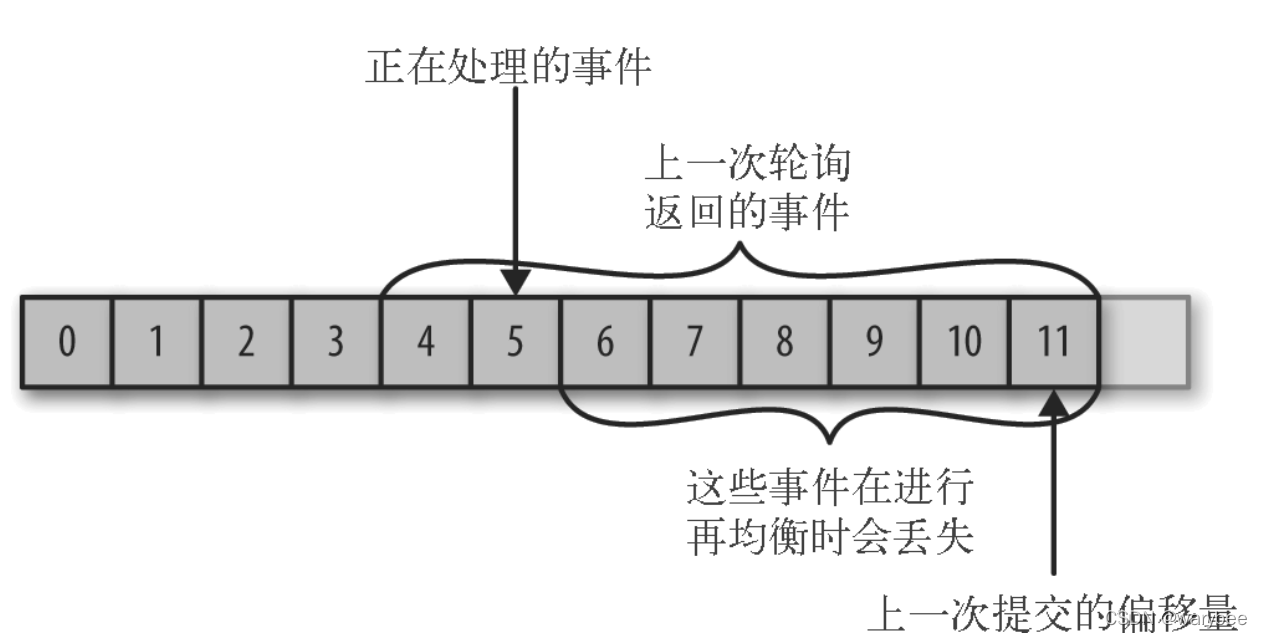
2.1 消息丢失
如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
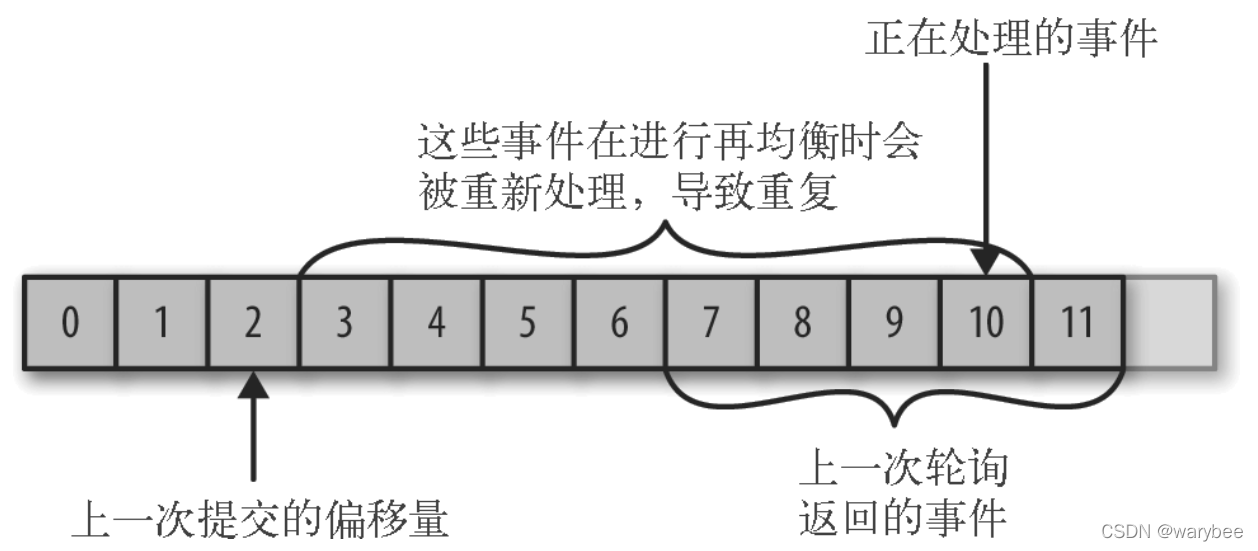
2.2 消息重复消费
如果提交的位移(offset)量小于消费者实际处理的最后一个消息的位移(offset)量,处于两个位移(offset)之间的消息会被重复处理。
3.1 自动提交
自动提交是KafkaConsumer API中的默认提交方式。
自动提交,需要配置两个参数:
enable.auto.commit=true 的时候代表自动提交位移。** **auto.commit.interval.ms=50000 auto.commit.interval.ms默认值是5s,即kafka每隔5s会帮你自动提交一次位移。自动位移提交的动作是在 poll()方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。假如消费数据量特别大,可以设置的短一点。
1 | //设置自动提交enable.auto.commit=true,(enable.auto.commit默认为就是true) |
3.2 手动同步提交
手动提交,则是指你要自己提交位移,Kafka Consumer 压根不管。
开启手动提交,把enable.auto.commit=false,用commitSync()提交由poll方法返回的最新偏移量。该方法为同步操作,等待直到 offset 被成功提交才返回。
1 | //设置手动提交 |
手动同步提交会 调用commitSync方法 时,Consumer 处于阻塞状态,直到Broker 返回结果,这样就会限制应用程序的吞吐量。虽然可以通过降低提交频率来提升吞吐量,但一旦发生再均衡,会增加重复消息的数量。
3.4 手动异步提交
异步提交使用commitAsync();方法。
1 | //设置手动提交 |
异步提交回调函数
1 | consumer.commitAsync(new OffsetCommitCallback() { |
3.5 同步异步组合提交 如果提交失败发生在关闭消费者或者再均衡前的最后一次提交,那么就要确保提交能够成功。这个时候就需要使用同步异步组合提交。
1 | //设置自动提交enable.auto.commit=true,(enable.auto.commit默认为就是true) |
1.同分组下测试
1.1测试一
1.1.1测试环境
Topic为lsztopic7,并生产30条信息。lsztopic7详情:

创建组为“testtopi7”的consumer,将enable.auto.commit设置为false,不提交offset。依次更改auto.offset.reset的值。此时查看offset情况为:

1.1.2测试结果
earliest 客户端读取30条信息,且各分区的offset从0开始消费。 latest 客户端读取0条信息。 none 抛出NoOffsetForPartitionException异常。

1.1.3测试结论
新建一个同组名的消费者时,auto.offset.reset值含义: earliest 每个分区是从头开始消费的。 none 没有为消费者组找到先前的offset值时,抛出异常
1.2测试二
1.2.1测试环境
测试场景一下latest时未接受到数据,保证该消费者在启动状态,使用生产者继续生产10条数据,总数据为40条。
1.2.2测试结果
latest 客户端取到了后生产的10条数据
1.2.3测试结论
当创建一个新分组的消费者时,auto.offset.reset值为latest时,表示消费新的数据(从consumer创建开始,后生产的数据),之前产生的数据不消费。
1.3测试三
1.3.1测试环境
在测试环境二,总数为40条,无消费情况下,消费一批数据。运行消费者消费程序后,取到5条数据。 即,总数为40条,已消费5条,剩余35条。

1.3.2测试结果
earliest 消费35条数据,即将剩余的全部数据消费完。
latest 消费9条数据,都是分区3的值。 offset:0 partition:3 offset:1 partition:3 offset:2 partition:3 offset:3 partition:3 offset:4 partition:3 offset:5 partition:3 offset:6 partition:3 offset:7 partition:3 offset:8 partition:3
none 抛出NoOffsetForPartitionException异常。
1.3.3测试结论
earliest 当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费。 latest 当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据。 none 当该topic下所有分区中存在未提交的offset时,抛出异常。
1.4测试四
1.4.1测试环境
再测试三的基础上,将数据消费完,再生产10条数据,确保每个分区上都有已提交的offset。 此时,总数为50,已消费40,剩余10条

1.4.2测试结果
none 消费10条信息,且各分区都是从offset开始消费 offset:9 partition:3 offset:10 partition:3 offset:11 partition:3 offset:15 partition:0 offset:16 partition:0 offset:17 partition:0 offset:18 partition:0 offset:19 partition:0 offset:20 partition:0 offset:5 partition:2
1.4.3测试结论
值为none时,topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常。
2.不同分组下测试
2.1测试五
2.1.1测试环境
在测试四环境的基础上:总数为50,已消费40,剩余10条,创建不同组的消费者,组名为testother7

2.1.2 测试结果
earliest 消费50条数据,即将全部数据消费完。
latest 消费0条数据。
none 抛出异常
2.1.3测试结论
组与组间的消费者是没有关系的。 topic中已有分组消费数据,新建其他分组ID的消费者时,之前分组提交的offset对新建的分组消费不起作用
参考: