前不久,想写写kafka的consumer,就按照官方API写了下面这一段代码,但是总是打印不出东西。返回的records是没有东西的。于是就研究了一下这个poll方法到底是怎么执行的。调试了很久,终于弄清楚了哪里有问题
代码
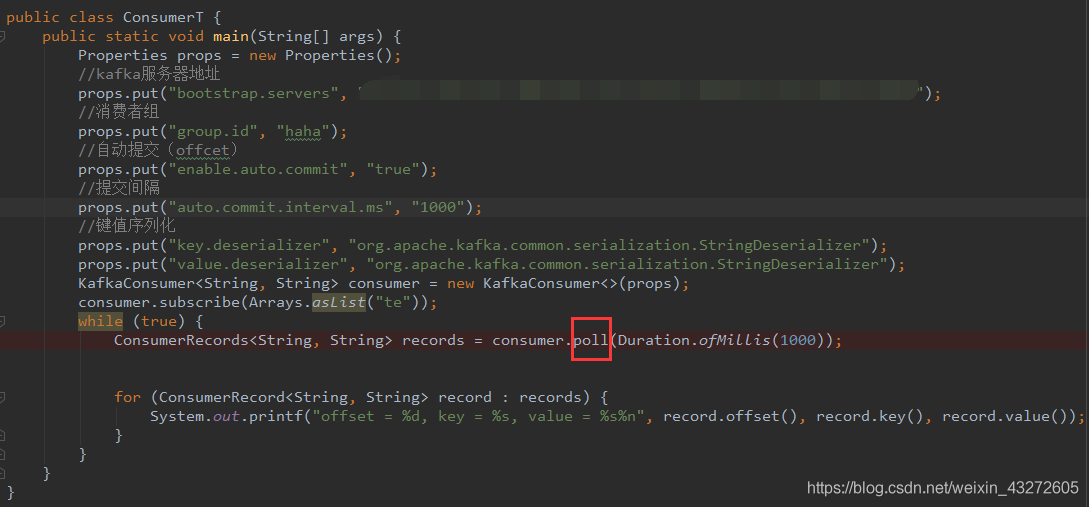
第一步,进入这个poll方法
1 |
|
注意上面的updateAssig
nmentMetadataIfNeeded 这个方法,我就是卡在了这里,我就是在这里返回了它的empty,导致返回的的结果也是空,最后打印不出东西。
先来详细看看这个方法
进入updateAssignmentMetadataIfNeeded方法
1 | boolean updateAssignmentMetadataIfNeeded(final Timer timer) { |
这是个判断,如果返回了false,那么就会让上面的那个结果为empty。而要返回false,必须知道coordinator!=null && !coordinator.poll(timer) 返回true。
下面东西有点儿烧脑,先来看看Coordinator
Coordinator
Kafka的coordiantor要做的事情就是group management,就是要对一个团队(或者叫组)的成员进行管理。Group management就是要做这些事情:
- 维持group的成员组成。这包括允许新的成员加入,检测成员的存活性,清除不再存活的成员。
- 协调group成员的行为。
Kafka为其设计了一个协议,就收做Group Management Protocol.
很明显,consumer group所要做的事情,是可以用group management 协议做到的。而cooridnator, 及这个协议,也是为了实现不依赖Zookeeper的高级消费者而提出并实现的。只不过,Kafka对高级消费者的成员管理行为进行了抽象,抽象出来group management功能共有的逻辑,以此设计了Group Management Protocol, 使得这个协议不只适用于Kafka consumer(目前Kafka Connect也在用它),也可以作为其它"group"的管理协议。
这是AbstractCoordinator源码的一段注释,它告诉了我们broker的coordinator的一些知识点
这个coordinator是有两种,一种是在broker,一种是在Concumer端
Broker端:
在Broker端,Kafka的group management protocol包括以下的动作序列:
- Group Registration:Group的成员需要向cooridnator注册自己,并且提供关于成员自身的元数据(比如,这个消费成员想要消费的topic)
- Group/Leader Selection:cooridnator确定这个group包括哪些成员,并且选择其中的一个作为leader。
- State Assignment: leader收集所有成员的metadata,并且给它们分配状态(state,可以理解为资源,或者任务)。
- Group Stabilization: 每个成员收到leader分配的状态,并且开始处理。
1 | 所有的成员要先向coordinator注册,由coordinator选出leader, 然后由leader来分配state。单个Kafka集群可能会存在着比broker的数量大得多的消费者和消费者组,而消费者的情况可能是不稳定的,可能会频繁变化,每次变化都需要一次协调,如果由broker来负责实际的协调工作,会给broker增加很多负担。所以,从group memeber里选出来一个做为leader,由leader来执行性能开销大的协调任务, 这样把负载分配到client端,可以减轻broker的压力,支持更多数量的消费组。 |
Consumer端:
private final ConsumerCoordinator coordinator;这个是consumer端的
ConsumerCoordinator是KafkaConsumer的一个成员变量,所以每个消费者都要自己的ConsumerCoordinator,消费者的ConsumerCoordintor只是和服务端的GroupCoordinator通信的介质。
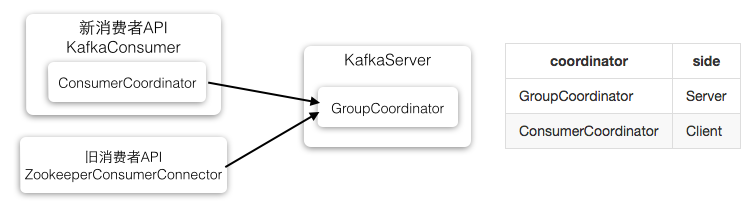
每个KafkaServer都有一个GroupCoordinator实例,服务端的GroupCoordinator管理消费组成员和offset,它可以管理多个消费组(因为Broker本身即使存储一个topic的消息,也可以被不同的消费组订阅)。注意:组成员的状态管理(比如GroupMetadata)是在服务端的GroupCoordinator完成的,而不是由消费组的ConsumerCoordinator完成(因为消费者只能看到自己的,无法看到和自己同组的其他成员)。
!coordinator.poll(timer)条件 进入到poll里面,源码如下
同步更新 coordinator - 确保我们的 consumer group 的 coordinator 是最新的。 更新拉取的位移 - 确保当前 consumer 分配的分区更新其相应的拉取位移,如果没有更新到的话,consumer 就会使用 auto.offset.reset 来更新分区的拉取位移(设置为最早位移、最近位移或者抛错)。
1 | public boolean poll(Timer timer) { |
你可能会好奇为什么 consumer 需要报告它的请求,实际上调用 poll 方法去拉取数据是你的应用自己的事,然后 Kafka 并不是很信任你,它可能怀疑你在尸位素餐。所以作为预防,consumer 会记录你多久调用一次 poll 方法,一旦这个间隔超过了指定值 max.poll.interval.ms,那么当前 consumer 就会从消费者组中离开,这样其他 consumer 就可以接盘当前 consumer 的工作了
看清楚上面我写的注释,带*号的位置,我就是在那里除了问题,不能和Broker建立连接,所以出现了问题。那么我就只能通过自己的服务器检查咋回事。
最后是因为一个节点端口不能通信,由于是别人名下的一个服务器,我也动不了端口,没有任何权限,就只能换一台服务器,终于,我们这边的ConsumerCoordinator终于和Broker端的CoordinatorGroup建立了连接。
体会
通过这次排错,我特意研究了一下源码,还真是有用。比较好玩。kafka的源码好像也不是很多。实现一个简单消息队列应该挺不错的。
以后找错不用先找博客,先看看别人的代码怎么运作的。这样能够从根本找出问题。
Kafka-当调用 Kafka Consumer 的 poll 方法时发生了什么?kafkaconsumer.poll小满锅lock的博客-CSDN博客