序言 搭建完了Rancher2.4.X,整理一下知识点,其中包括了K8S.方便后面我们玩.知识点当然是持续更新
K8S
K8S是容器编排调度引擎.提供了如下的内容:
- 简化应用部署
- 提高硬件资源利用率
- 健康检查和自修复
- 自动扩容缩容
- 服务发现和负载均衡
K8S内部的元素(从元素上看K8S是很复杂的)
k8s集群由Master节点和Node(Worker)节点组成。
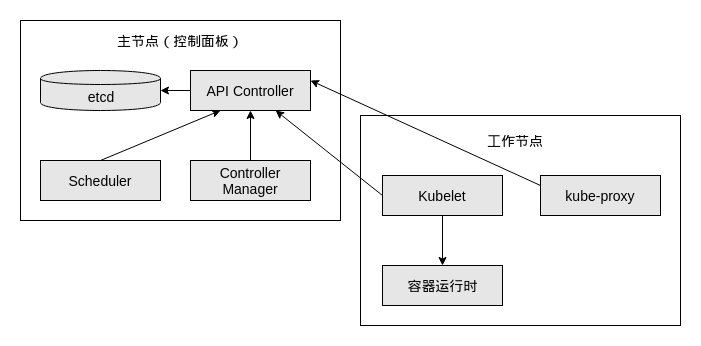
Master节点
Master节点指的是集群控制节点,管理和控制整个集群,基本上k8s的所有控制命令都发给它,它负责具体的执行过程。(如下的机器上运行的程序都可以在Rancher起来后通过docker ps看到----[email protected])
在Master上主要运行着:
- Kubernetes Controller Manager(kube-controller-manager):k8s中所有资源对象的自动化控制中心,维护管理集群的状态,比如故障检测,自动扩展,滚动更新等。
- Kubernetes Scheduler(kube-scheduler): 负责资源调度,按照预定的调度策略将Pod调度到相应的机器上。(这里的POD即最小的工作单元)
- etcd:保存整个集群的状态。----这个东西在Rancher2.5.1中一直报错~~~
Node节点
除了master以外的节点被称为Node或者Worker节点,可以在master中使用命令 kubectl get nodes查看集群中的node节点。每个Node都会被Master分配一些工作负载(Docker容器)—工作负载就是容器了,当某个Node宕机时,该节点上的工作负载就会被Master自动转移到其它节点上。在Node上主要运行着:
- kubelet:负责Pod对应的容器的创建、启停等任务,同时与Master密切协作,实现集群管理的基本功能
- kube-proxy:实现service的通信与负载均衡
- docker(Docker Engine):Docker引擎,负责本机的容器创建和管理
pod —— k8s 调度的最小单元
一个 pod 包含一组容器,一个 pod 不会跨越多个工作节点
- pod 相当于逻辑主机,每个 pod 都有自己的 IP 地址
- pod 内的容器共享相同的 IP 和端口空间
- 默认情况下,每个容器的文件系统与其他容器完全隔离
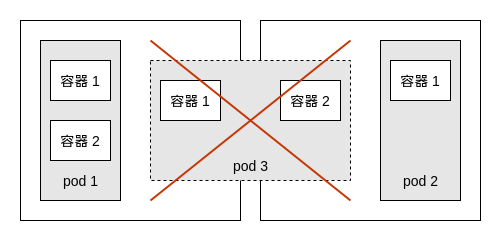
controller
k8s通常不会直接创建pod,而是通过controller来管理pod的。controller中定义了pod的部署特性,比如有几个剧本,在什么样的node上运行等。
为了满足不同的业务场景,k8s提供了多种controller,包括deployment、replicaset、daemonset、statefulset、job等。(如下的副本就是容器的COPY可以这么理解–[email protected])
- deployment: 是最常用的controller。deployment可以管理pod的多个副本,并确保pod按照期望的状态运行。
- replicaset: 实现了pod的多副本管理。使用deployment时会自动创建replicaset,也就是说deployment是通过replicaset来管理pod的多个副本的,我们通常不需要直接使用replicaset。
- daemonset:用于每个node最多只运行一个pod副本的场景。正如其名称所示的,daemonset通常用于运行daemon。
- statefuleset:能够保证pod的每个副本在整个生命周期中名称是不变的,而其他controller不提供这个功能。当某个pod发生故障需要删除并重新启动时,pod的名称会发生变化,同时statefulset会保证副本按照固定的顺序启动、更新或者删除。
- job:用于运行结束就删除的应用,而其他controller中的pod通常是长期持续运行的。
service(通过Service可以访问放置在Pod中的Docker应用)
deployment可以部署多个副本,每个pod 都有自己的IP,外界如何访问这些副本那?答案是service
k8s的 service定义了外界访问一组特定pod的方式。service有自己的IP和端口,service为pod提供了负载均衡。
k8s运行容器pod与访问容器这两项任务分别由controller和service执行。
namespace(逻辑隔离)
cluster是 计算、存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用。
可以将一个物理的cluster逻辑上划分成多个虚拟cluster,每个cluster就是一个namespace。不同的namespace里的资源是完全隔离的。
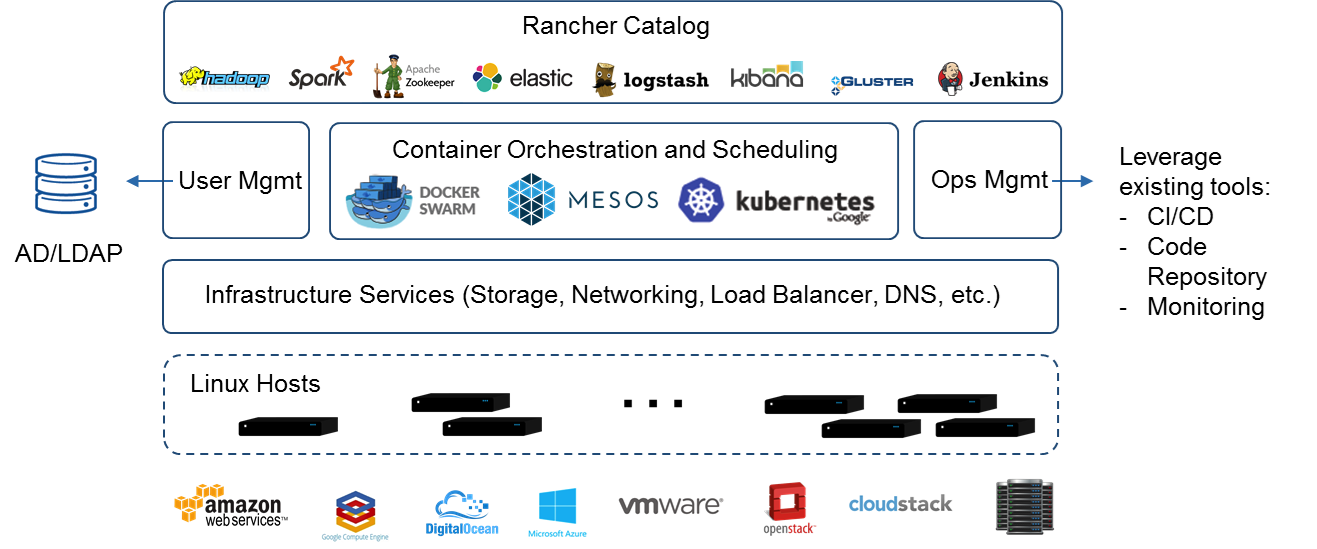
Rancher概览(https://rancher.com/docs/rancher/v1.6/zh/)
Rancher是一个开源的企业级容器管理平台。通过Rancher,企业再也不必自己使用一系列的开源软件去从头搭建容器服务平台。Rancher提供了在生产环境中使用的管理Docker和Kubernetes的全栈化容器部署与管理平台。
Rancher由以下四个部分组成:
基础设施编排
Rancher可以使用任何公有云或者私有云的Linux主机资源。 Linux主机可以是虚拟机,也可以是物理机Rancher仅需要主机有CPU,内存,本地磁盘和网络资源。从Rancher的角度来说,一台云厂商提供的云主机和一台自己的物理机是一样的。
Rancher为运行容器化的应用实现了一层灵活的基础设施服务。Rancher的基础设施服务包括网络, 存储, 负载均衡, DNS和安全模块。Rancher的基础设施服务也是通过容器部署的,所以同样Rancher的基础设施服务可以运行在任何Linux主机上。
容器编排与调度
很多用户都会选择使用容器编排调度框架来运行容器化应用。Rancher包含了当前全部主流的编排调度引擎,例如Docker Swarm, Kubernetes, 和Mesos 。同一个用户可以创建Swarm或者Kubernetes集群。并且可以使用原生的Swarm或者Kubernetes工具管理应用。-----------(使用原生的工具干嘛,那Rancher不是白弄了,希望不会用到-----cuiyaonan2000)
除了Swarm,Kubernetes和Mesos之外, Rancher还支持自己的Cattle容器编排调度引擎。Cattle被广泛用于编排Rancher自己的基础设施服务以及用于Swarm集群,Kubernetes集群和Mesos集群的配置,管理与升级。
应用商店
Rancher的用户可以在应用商店里一键部署由多个容器组成的应用**。用户可以管理这个部署的应用,并且可以在这个应用有新的可用版本时进行自动化的升级。Rancher提供了一个由Rancher社区维护的应用商店,其中包括了一系列的流行应用。**Rancher的用户也可以创建自己的私有应用商店。
企业级权限管理
Rancher支持灵活的插件式的用户认证。支持Active Directory,LDAP, Github等 认证方式。 Rancher支持在环境级别的基于角色的访问控制 (RBAC),可以通过角色来配置某个用户或者用户组对开发环境或者生产环境的访问权限。
下图展示了Rancher的主要组件和功能: